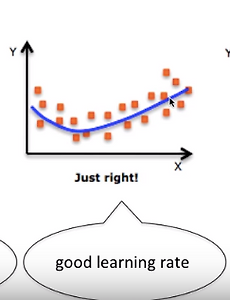
머신러닝12 Stacking - 스태킹 stacking algorism 머신러닝 결과를 다른 알고리즘의 입력으로 활용 상위 개념의 알고리즘의 결과를 다른 입력에 반영시킬 수 도 있다, 알고리즘을 어떻게 쌓아 올릴지는 임의로 설정할 수 있지만 실제로는 오컴의 면도날 원리에 따라 가급적 단순한 형태로 구축하는 것이 좋다 2020. 8. 6. Boosting - 부스팅 가중치를 사용해 개별 학습기의 강도를 잘 조절하는 데 이런 기법을 boosting이라고 함 지도학습 관점에서, 약한학습기를 베이스라인보다는 야간 좋은 정도의 학습기로 정의 개별적으로 봤을 때는 약간의 부스팅이지만, 많은 데이터로 봤을 때는 놀라운 결과를 만들어낼 수 도 있다 boosting algorism 가중치를 어떻게 적용하느냐에 따라 여러 가지가 있음 시험 공부를 한다고 예를 들면, 잘 안 풀리는 문제는 배제하고, 난이도가 높은 문제에 집중하는 식 이미지에서 얼굴을 추적하는 기술에서, 일반적으로 이미지에서 얼굴이 없는 영역이 더 크기 때문에, 분류기에서 연쇄적으로 매 단계에서 얼굴이 없는 부분을 제거해 나간다 2020. 8. 5. 배깅 - bagging algorism bagging algorism bootstrap aggregating 라고도 하며, Leo Breiman 이 1994년 머신러닝 문제에 적용하며 처음 소개 부트스트래핑 : 통계적 기법 : 계산 과정에서 샘플링 기법을 적용하는 방법 : 기존 데이터로부터 무작위로 샘플 데이터를 추출해서 새로운 데이터세트를 만들어 냄 : 산순 평균, 분산, 정량적 측정치를 계산할 수 있는 데이터를 분석할 때 사용 오버피팅 발생 가능성을 낮추는 목적 교환방법을 이용하는 샘플링을 통해 원본 데이터에서 새로운 데이터세트를 만든다 앞에서 만든 데이터세트 각각에 모델을 학습 평균화 또는 최다 득표 보팅 결과를 바탕으로 모델의 결과를 조합 2020. 8. 4. Regularization - 복잡도에 패널티 주기, 오버피팅 피하기 Early stopping 모델이 복잡해지기 전에 막음 학습, 검증, 평가로 데이터를 3등분(7:2:1)하여 모델을 만드는 초기부터 검증하며 복잡도를 막음 단점: 데이터량이 낭비됨, 검증/평가 데이터 Noisy input 부족한 데이터를 늘리기위해 노이즈를 추가하여 데이터를 늘림 단점: 오분류된 샘플에 노이즈를 추가하여 데이터를 늘렸다면 안좋은 데이터가 늘어나게됨 drop-out 일부 파라미터를 의도적으로 제거하는 방법 인공신경망에서 일부 은닉층의 몇몇 노드를 비활성화하여 모델을 만듬 복잡도 패널티 L1, L2 reqularization - 모델의 복잡도에 패널티를 줌 Pruning / feature selection 복잡하거나, 불필요한 가지/feature를 제거해서 모델을 만듬 Ensemble 앙상블.. 2020. 8. 3. Overfitting, Undeffitting - 오버피팅, 언더피팅 Overfitting 이란? 학습데이터에 지나치게 일치하여 새로운 데이터를 올바르게 예측하지 못하는 것 새로운 데이터에 대한 성능이 좋지않음 Overfitting의 원인/특성 학습데이터세트에서 지나치게 많은 정보를 추출하는 경우 -> high variance (높은 분산) 모델을 데이터에 과하게 맞추려고 하는 경우 -> low bias (낮은 바이어스) Underfitting 이란 학습데이터에 모델이 올바르게 동작하지 않고, 테스트데이터에도 올바르게 동작하지 않는다 학습 데이터가 충분하지 않았거나, 패턴을 잡아내지 못했다는 것 Underfitting의 특성 high bias -> 예측 결과가 정답과는 거리가 멀다 low variance -> 예측 결과끼리의 차이는 별로 없는 생태 2020. 7. 31. 머신러닝 - 학습 데이터 속성 머신러닝 작업은 학습 데이터의 속성에 따라 나뉜다 비지도 학습 (Unsupervised learning) 레이블 없는 데이터 (unlabeled data) 로 데이터의 구조나, 패턴을 찾고 데이터를 그룹화한다 지도 학습 (Supervised learning) 레이블 데이터 (labeled data) 를 사용 학습 목표는 입력과 결과를 매핑시키는 룰을 찾는 것 ex> 얼굴인식, 음성인식, 상품추천, 영화추천, 영업실적 전망 1. 회귀 (regression) 연속적인 값을 학습하고 예측하는 것 집값 예측 등 2. 분류 (classification) 긍정/부정 같은 감성 분석이나 채무 불이행 예측 같은 레이블을 찾는 것 준지도 학습 학습단계에서 (소량의) 레이블데이터와 (대량의) 레이블이 없는 데이터를 사용 .. 2020. 7. 30. 이전 1 2 다음